qthreads
Intelligent GPU, Multi-Core CPU, and FPGA Accelerators
Single Thread to Multithreaded Executable
x86, ARM, RISCV, Apple M1 CPU
nVidia and AMD GPU
AMD FPGA
All Automatically from Same Source Code
The Past
THERE WAS NO HETEROGENEOUS COMPUTE DEVELOPMENT PLATFORM
Today
SW DEVELOPERS EASILY DEVELOP & DEPLOY APPLICATIONS
Multicore Acceleration
Proven Results
")
Multithreading is all about intelligence based code and data analysis
Generating multithreaded code from unmodified single thread source requires exhaustive analysis of loops, understanding data access patterns and knowledge of the target architecture. Unlike alternative approaches qthreads will automatically generate multithreaded code without the additions of pragmas and user directives. qthreads takes single threaded code and generates multithreaded C++ code that works with any C++ compiler. The number of threads is runtime specified depending on hardware availability and optimized execution. Profiling is an integral part of the process to ensure loops that contribute little execution time are not threaded and loops that contribute the majority of execution time are threaded. The reason loops are not multithreaded is clearly reported. If profiling indicates a high execution loop is not threaded educated steps can be taken by the developer to alleviate issues that preclude multithreading. The same unmodified source can be used to target x86, ARM, RISCV, embedded, monolithic heterogenous SOCs and servers. Lastly, executing code unthreaded or any number of multiple threads will produce identical results. Not the case with other technologies. Intelligence based multithreading produces superior results with dramatically less resource investment and time. It is time to adopt a new heterogeneous SW development platform.
FPGA Acceleration
Proven Results
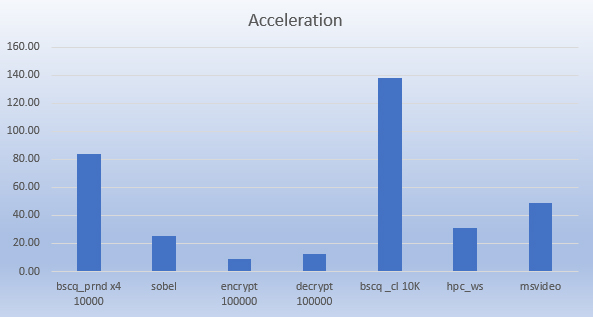
Up to 100x plus performance gain
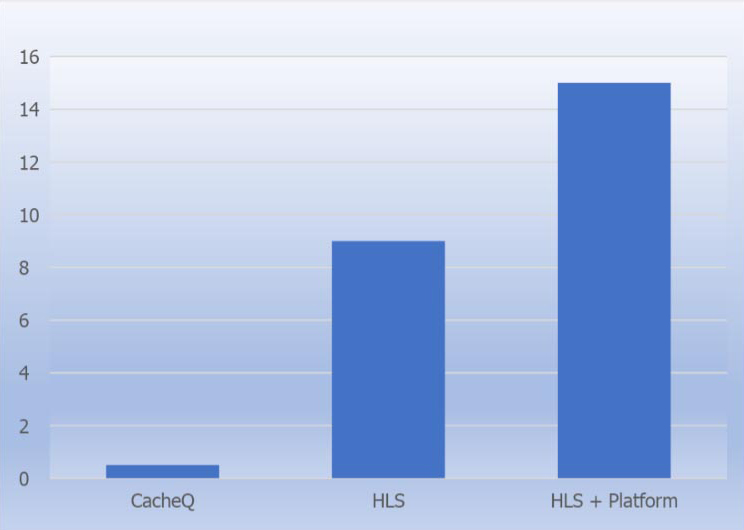
Greater than 15x reduction in development time
Performance improvements using FPGAs is all about accelerating loops.
If N is the number of iterations of a loop and C is the number of cycles the execution time is roughly (N*C)/(clock rate). On a fully pipelined FPGA implementation the execution time is (N+C)/(clock rate). QCC automatically pipelines loops. The fully pipelined loop is integrated with an application specific many port cached memory architecture ensuring high bandwidth data movement. In addition, with a command line option loops can be unrolled to deliver significantly higher performance bound by hardware resource constraints.
Developing solutions for FPGAs has been the domain of HW developers. Software applications must be extensively modified to achieve the desired performance goals. In most cases this is a nine to twelve month process. CacheQ delivers a complete development and deployment platform for SW developers. Partitioning between host and accelerators is handled by the platform. Performance simulation, profiling, resource estimates and memory configuration are supported prior to implementation. All the capabilities required to support many ported dynamically allocated memory are available to the developer. A complete development platform requiring limited code modifications dramatically shortens development time and improves system quality.
The Cacheq Development Flow

The Technology
Request a Demo
Request a demo to learn more about our acceleration and distributed computing solution.