The Opportunity
The recognized slowing of Moore’s law is creating significant new compute opportunities. The compute landscape is changing to an environment of heterogeneous platforms across the data center and edge.
Problems of the Past
To address compute challenges x86 and ARM architecture have devices supporting more and more cores and are also being augmented with GPUs, FPGAs and custom ML accelerators. However, SW developers do not have the platform to deliver solutions on these new architectures. Existing platforms are focused on single core performance and do not adequately support the spectrum of heterogeneous accelerators.

The CacheQ Solution of Today
The CacheQ QCC development platform enables SW developers to easily develop, deploy and orchestrate applications across multicore devices and heterogeneous distributed compute architectures delivering significant increases in application performance, reduced power and at the same time dramatically reducing development time.
Proven Multicore Results
Multithreaded performance improvements are all about limiting data movement between cores and multithreading the appropriate code.
Developing multicore solutions requires extensive knowledge of data movement, access patterns, processor architecture and compiler nuances. CacheQ’s qthread technology performs extensive intelligence based application analysis to determine which code can be multithreaded. Multithreading is automatically determined by the tool analysis requiring no code modifications by the SW developer. Reporting is available which informs the SW developer which code cannot be multithreaded. Profiling information can be generated to determine which code consumes the most time. The number of threads is specified at run times enabling the optimal use of compute resources. All of these capabilities are easily integrated into existing development platforms.
")
Proven FPGA Results
If N is the number of iterations of a loop and C is the number of cycles the execution time is roughly (N*C)/(clock rate). On a fully pipelined implementation the execution time is (N+C)/(clock rate). QCC automatically pipelines loops. The fully pipelined loop is integrated with an application specific many port cached memory architecture ensuring high bandwidth data movement. In addition, with a command line option loops can be unrolled to deliver significantly higher performance bound by hardware resource constraints.
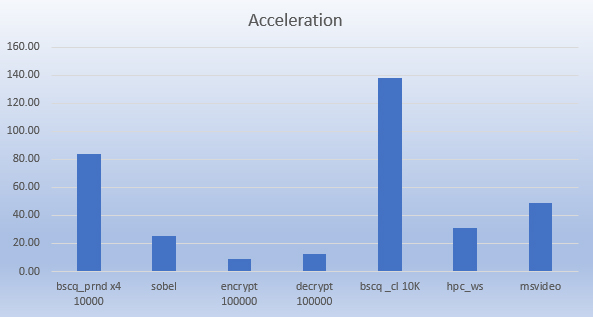
Up to 100x plus performance gain
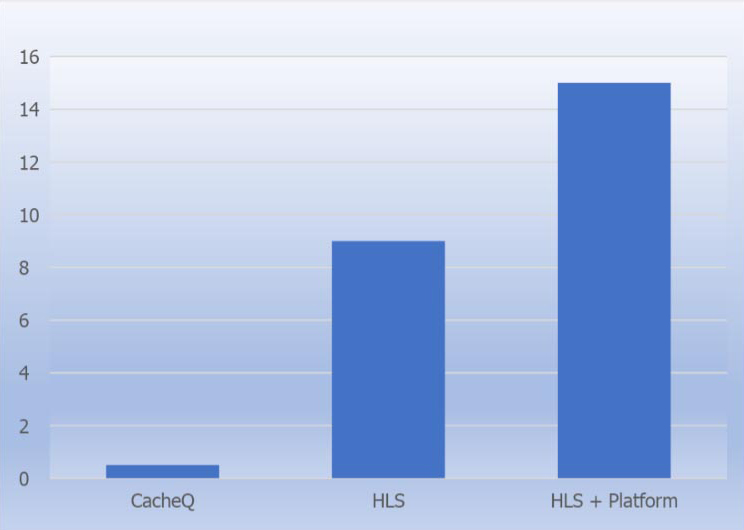
Greater than 15x reduction in development time